S's PlayGround
Testing & Educational Purpose
import pandas as pd
data = pd.read_csv(r"C:\Users\Lena\Documents\PASCA\Datasets\Kaggle - Fatalities in Palestine Israel\archive\fatalities_isr_pse_conflict_2000_to_2023.csv")
data.head()
| name | date_of_event | age | citizenship | event_location | event_location_district | event_location_region | date_of_death | gender | took_part_in_the_hostilities | place_of_residence | place_of_residence_district | type_of_injury | ammunition | killed_by | notes | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 'Abd a-Rahman Suleiman Muhammad Abu Daghash | 2023-09-24 | 32.0 | Palestinian | Nur Shams R.C. | Tulkarm | West Bank | 2023-09-24 | M | NaN | Nur Shams R.C. | Tulkarm | gunfire | live ammunition | Israeli security forces | Fatally shot by Israeli forces while standing ... |
| 1 | Usayed Farhan Muhammad 'Ali Abu 'Ali | 2023-09-24 | 21.0 | Palestinian | Nur Shams R.C. | Tulkarm | West Bank | 2023-09-24 | M | NaN | Nur Shams R.C. | Tulkarm | gunfire | live ammunition | Israeli security forces | Fatally shot by Israeli forces while trying to... |
| 2 | 'Abdallah 'Imad Sa'ed Abu Hassan | 2023-09-22 | 16.0 | Palestinian | Kfar Dan | Jenin | West Bank | 2023-09-22 | M | NaN | al-Yamun | Jenin | gunfire | live ammunition | Israeli security forces | Fatally shot by soldiers while firing at them ... |
| 3 | Durgham Muhammad Yihya al-Akhras | 2023-09-20 | 19.0 | Palestinian | 'Aqbat Jaber R.C. | Jericho | West Bank | 2023-09-20 | M | NaN | 'Aqbat Jaber R.C. | Jericho | gunfire | live ammunition | Israeli security forces | Shot in the head by Israeli forces while throw... |
| 4 | Raafat 'Omar Ahmad Khamaisah | 2023-09-19 | 15.0 | Palestinian | Jenin R.C. | Jenin | West Bank | 2023-09-19 | M | NaN | Jenin | Jenin | gunfire | live ammunition | Israeli security forces | Wounded by soldiers’ gunfire after running awa... |
missing_values = data[['age', 'type_of_injury', 'killed_by', 'citizenship']].isnull().sum()
missing_values
age 129
type_of_injury 291
killed_by 0
citizenship 0
dtype: int64
median_age = data['age'].median()
data['age'].fillna(median_age, inplace=True)
mode_type_of_injury = data['type_of_injury'].mode()[0]
data['type_of_injury'].fillna(mode_type_of_injury, inplace=True)
updated_missing_values = data[['age', 'type_of_injury', 'killed_by', 'citizenship']].isnull().sum()
updated_missing_values
age 0
type_of_injury 0
killed_by 0
citizenship 0
dtype: int64
ammunition_distribution = data['ammunition'].value_counts()
type_of_injury_distribution = data['type_of_injury'].value_counts()
killed_by_distribution = data['killed_by'].value_counts()
ammunition_distribution, type_of_injury_distribution, killed_by_distribution
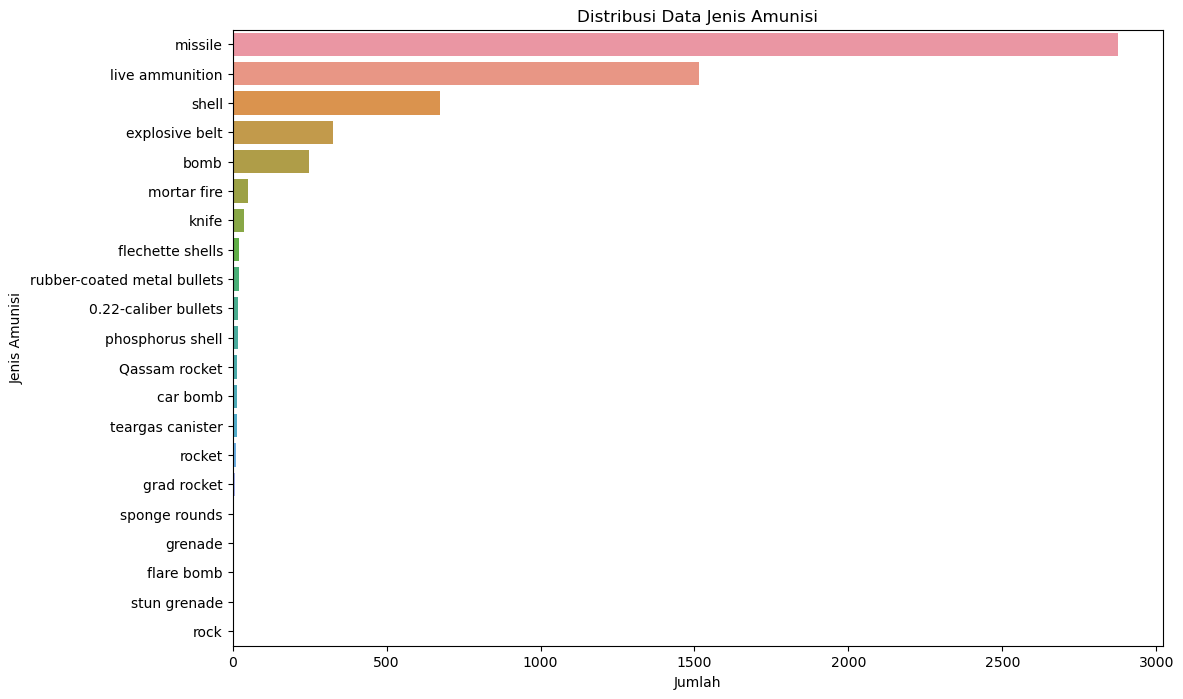
(missile 2877
live ammunition 1514
shell 675
explosive belt 326
bomb 249
mortar fire 51
knife 37
flechette shells 22
rubber-coated metal bullets 19
0.22-caliber bullets 16
phosphorus shell 16
Qassam rocket 15
car bomb 15
teargas canister 13
rocket 12
grad rocket 7
sponge rounds 2
grenade 2
flare bomb 1
stun grenade 1
rock 1
Name: ammunition, dtype: int64,
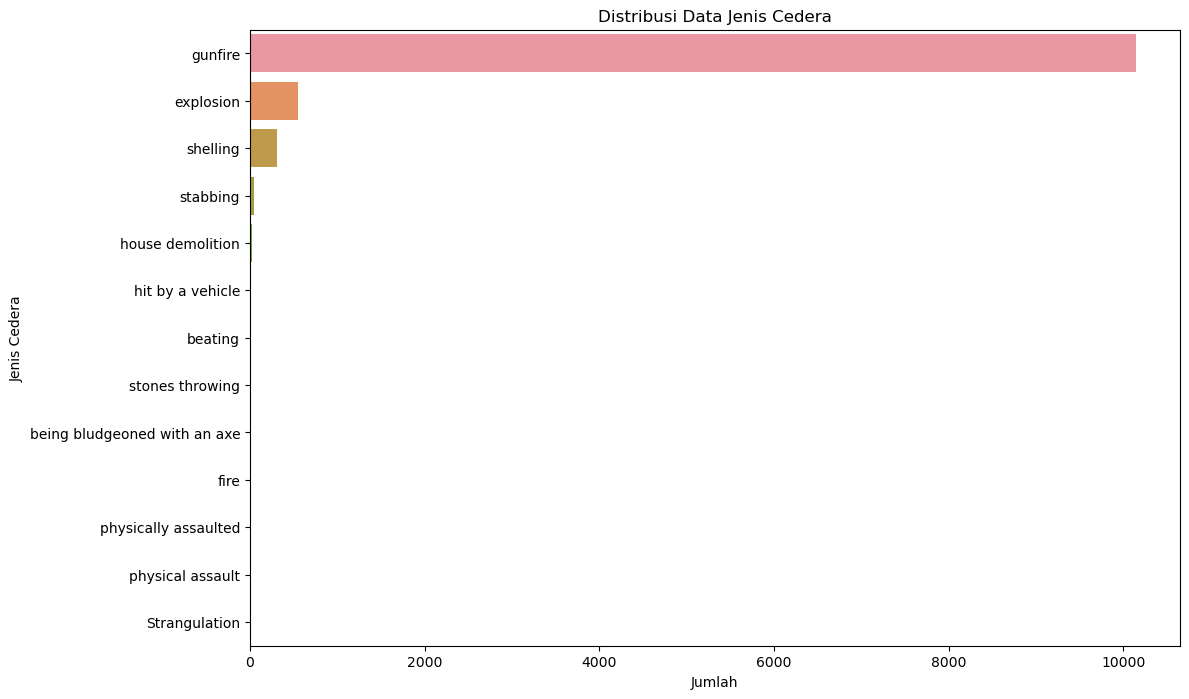
gunfire 10140
explosion 555
shelling 311
stabbing 48
house demolition 25
hit by a vehicle 18
beating 9
stones throwing 6
being bludgeoned with an axe 4
fire 4
physically assaulted 2
physical assault 1
Strangulation 1
Name: type_of_injury, dtype: int64,
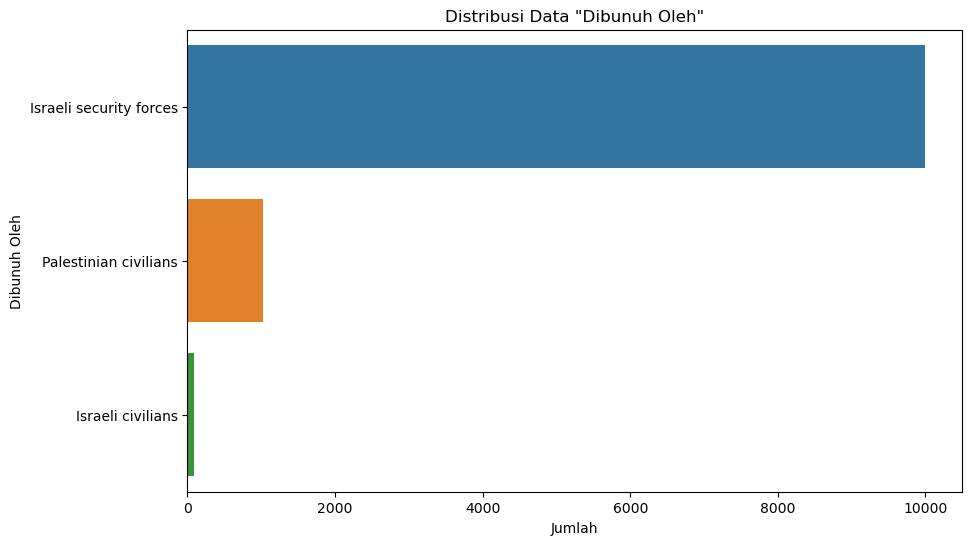
Israeli security forces 10000
Palestinian civilians 1028
Israeli civilians 96
Name: killed_by, dtype: int64)
#Pembuatan model prediksi
from sklearn.preprocessing import OneHotEncoder
features = data[['ammunition', 'type_of_injury']]
target = data['killed_by']
encoder = OneHotEncoder(sparse=False)
features_encoded = encoder.fit_transform(features)
encoded_feature_names = encoder.get_feature_names_out(['ammunition', 'type_of_injury'])
features_encoded_df = pd.DataFrame(features_encoded, columns=encoded_feature_names)
features_encoded_df.head()
| ammunition_0.22-caliber bullets | ammunition_Qassam rocket | ammunition_bomb | ammunition_car bomb | ammunition_explosive belt | ammunition_flare bomb | ammunition_flechette shells | ammunition_grad rocket | ammunition_grenade | ammunition_knife | ... | type_of_injury_explosion | type_of_injury_fire | type_of_injury_gunfire | type_of_injury_hit by a vehicle | type_of_injury_house demolition | type_of_injury_physical assault | type_of_injury_physically assaulted | type_of_injury_shelling | type_of_injury_stabbing | type_of_injury_stones throwing | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 35 columns
#Implementasi regresi logistik
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
X_train, X_test, y_train, y_test = train_test_split(features_encoded_df, target, test_size=0.3, random_state=42)
log_reg_model = LogisticRegression(max_iter=1000)
log_reg_model.fit(X_train, y_train)
y_pred = log_reg_model.predict(X_test)
classification_report_results = classification_report(y_test, y_pred)
classification_report_results
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
' precision recall f1-score support\n\n Israeli civilians 0.00 0.00 0.00 31\nIsraeli security forces 0.95 1.00 0.97 2986\n Palestinian civilians 0.93 0.61 0.74 321\n\n accuracy 0.95 3338\n macro avg 0.63 0.54 0.57 3338\n weighted avg 0.94 0.95 0.94 3338\n'
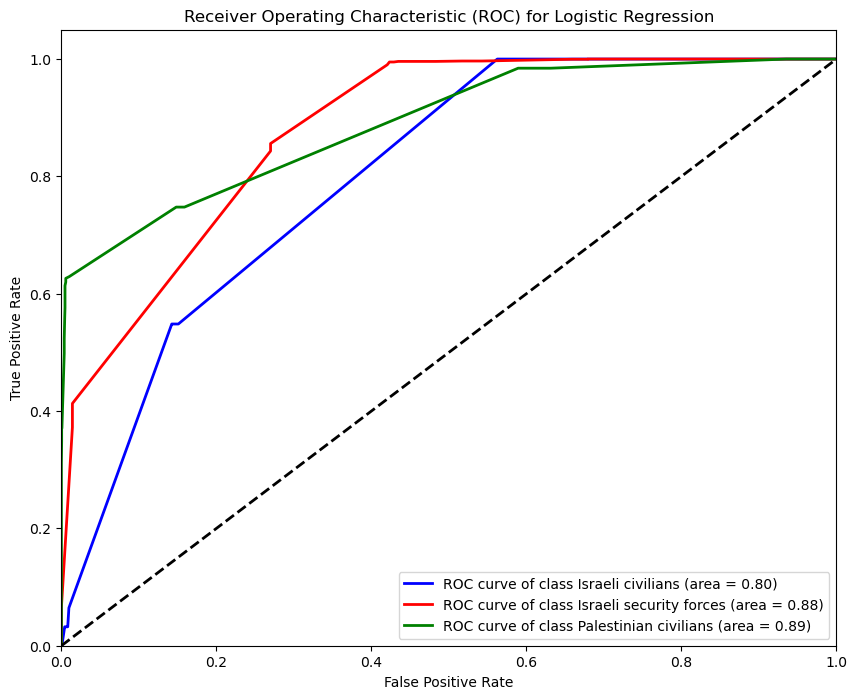
#Diagram ROC LR
from sklearn.metrics import roc_curve, auc, RocCurveDisplay
import matplotlib.pyplot as plt
fpr = dict()
tpr = dict()
roc_auc = dict()
n_classes = y_train.nunique()
classes = log_reg_model.classes_
y_test_bin = pd.get_dummies(y_test, columns=classes).to_numpy()
y_score = log_reg_model.predict_proba(X_test)
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
plt.figure(figsize=(10, 8))
colors = ['blue', 'red', 'green']
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(classes[i], roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) for Logistic Regression')
plt.legend(loc="lower right")
plt.show()
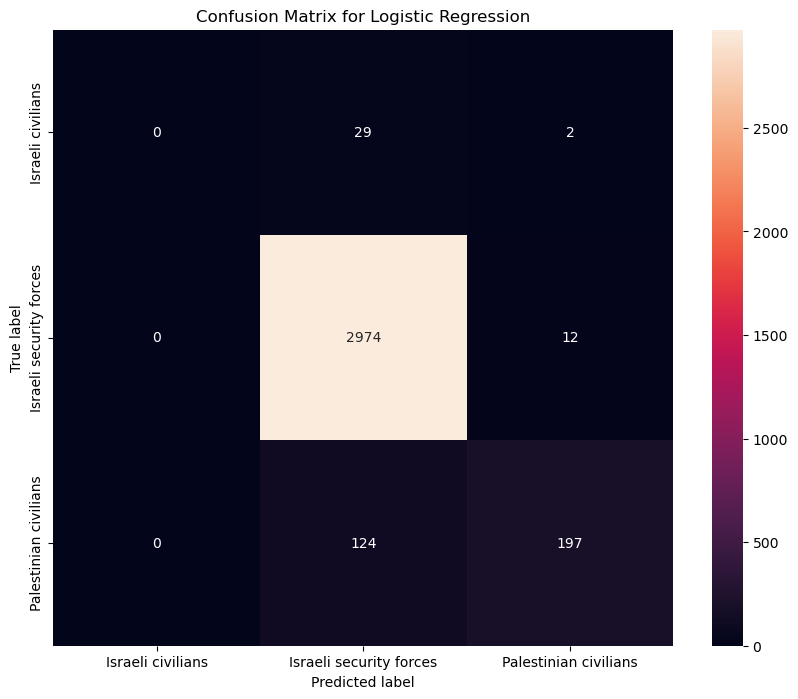
#Confusion matrix LR
from sklearn.metrics import confusion_matrix
import seaborn as sns
conf_mat = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat, annot=True, fmt="d",
xticklabels=log_reg_model.classes_,
yticklabels=log_reg_model.classes_)
plt.title('Confusion Matrix for Logistic Regression')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
#Implementasi SVM
from sklearn.svm import SVC
svm_model = SVC()
svm_model.fit(X_train, y_train)
y_pred_svm = svm_model.predict(X_test)
classification_report_svm = classification_report(y_test, y_pred_svm)
classification_report_svm
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
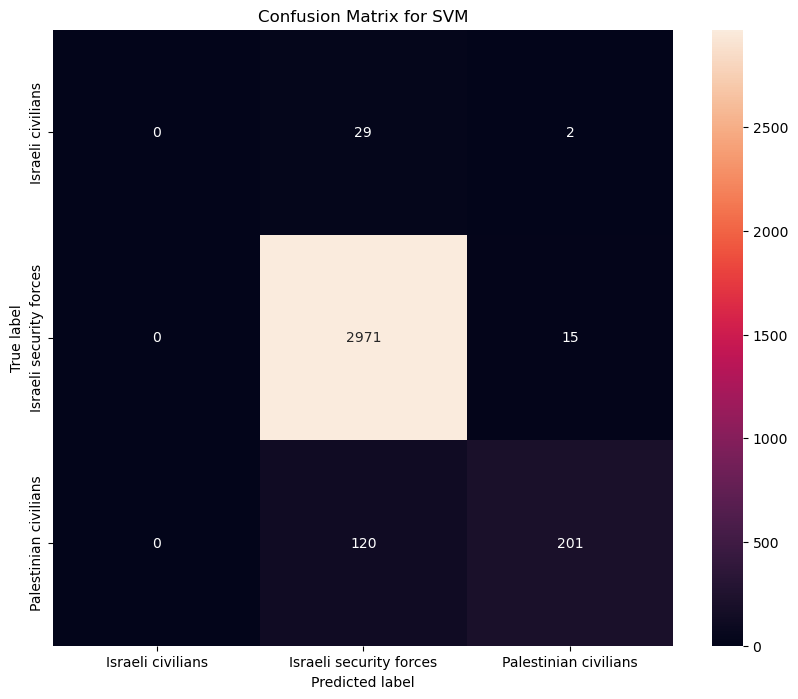
' precision recall f1-score support\n\n Israeli civilians 0.00 0.00 0.00 31\nIsraeli security forces 0.95 0.99 0.97 2986\n Palestinian civilians 0.92 0.63 0.75 321\n\n accuracy 0.95 3338\n macro avg 0.62 0.54 0.57 3338\n weighted avg 0.94 0.95 0.94 3338\n'
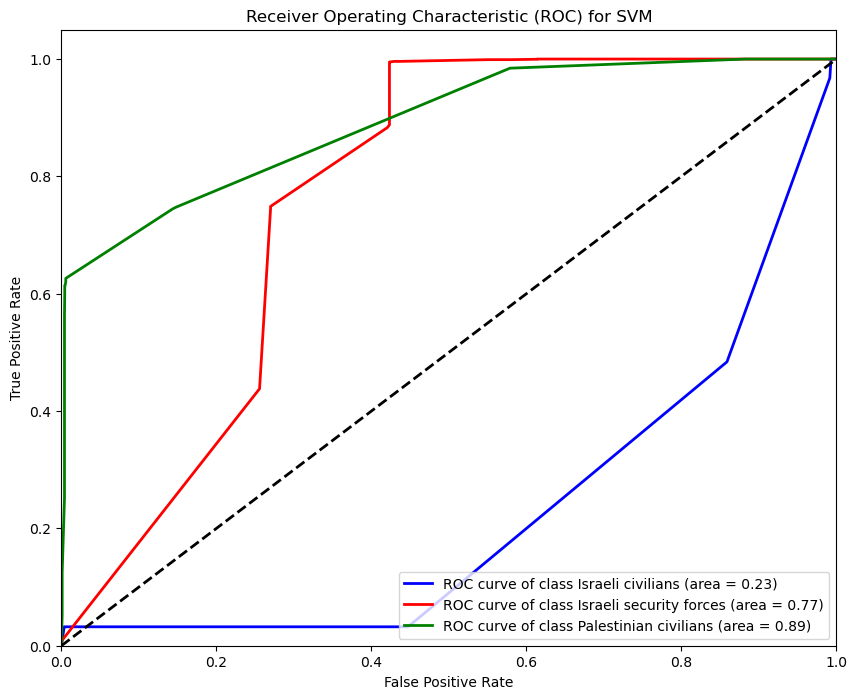
#Diagram ROC SVM
from sklearn.preprocessing import label_binarize
y_test_bin_svm = label_binarize(y_test, classes=classes)
y_score_svm = svm_model.decision_function(X_test)
fpr_svm = dict()
tpr_svm = dict()
roc_auc_svm = dict()
for i in range(n_classes):
fpr_svm[i], tpr_svm[i], _ = roc_curve(y_test_bin_svm[:, i], y_score_svm[:, i])
roc_auc_svm[i] = auc(fpr_svm[i], tpr_svm[i])
plt.figure(figsize=(10, 8))
for i, color in zip(range(n_classes), colors):
plt.plot(fpr_svm[i], tpr_svm[i], color=color, lw=2,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(classes[i], roc_auc_svm[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) for SVM')
plt.legend(loc="lower right")
plt.show()
#Confusion Matrix SVM
conf_mat_svm = confusion_matrix(y_test, y_pred_svm)
plt.figure(figsize=(10, 8))
sns.heatmap(conf_mat_svm, annot=True, fmt="d",
xticklabels=svm_model.classes_,
yticklabels=svm_model.classes_)
plt.title('Confusion Matrix for SVM')
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
#Perbandingan LR dan SVM
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy_lr = accuracy_score(y_test, y_pred)
precision_lr = precision_score(y_test, y_pred, average='weighted')
recall_lr = recall_score(y_test, y_pred, average='weighted')
f1_score_lr = f1_score(y_test, y_pred, average='weighted')
accuracy_svm = accuracy_score(y_test, y_pred_svm)
precision_svm = precision_score(y_test, y_pred_svm, average='weighted')
recall_svm = recall_score(y_test, y_pred_svm, average='weighted')
f1_score_svm = f1_score(y_test, y_pred_svm, average='weighted')
performance_comparison = pd.DataFrame({
'Metric': ['Accuracy', 'Precision', 'Recall', 'F1 Score'],
'Logistic Regression': [accuracy_lr, precision_lr, recall_lr, f1_score_lr],
'SVM': [accuracy_svm, precision_svm, recall_svm, f1_score_svm]
})
performance_comparison.set_index('Metric', inplace=True)
performance_comparison
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
C:\Users\Lena\anaconda3\lib\site-packages\sklearn\metrics\_classification.py:1318: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, msg_start, len(result))
| Logistic Regression | SVM | |
|---|---|---|
| Metric | ||
| Accuracy | 0.949970 | 0.950270 |
| Precision | 0.940563 | 0.940493 |
| Recall | 0.949970 | 0.950270 |
| F1 Score | 0.941623 | 0.942244 |
#Rubah menjadi persentase
performance_comparison_percentage = performance_comparison * 100
performance_comparison_percentage
| Logistic Regression | SVM | |
|---|---|---|
| Metric | ||
| Accuracy | 94.997004 | 95.026962 |
| Precision | 94.056332 | 94.049348 |
| Recall | 94.997004 | 95.026962 |
| F1 Score | 94.162253 | 94.224373 |
#Distribusi amunisi
plt.figure(figsize=(12, 8))
sns.countplot(y=data['ammunition'], order = data['ammunition'].value_counts().index)
plt.title('Distribusi Data Jenis Amunisi')
plt.xlabel('Jumlah')
plt.ylabel('Jenis Amunisi')
plt.show()
#Distribusi killed by
plt.figure(figsize=(10, 6))
sns.countplot(y=data['killed_by'], order=data['killed_by'].value_counts().index)
plt.title('Distribusi Data "Dibunuh Oleh"')
plt.xlabel('Jumlah')
plt.ylabel('Dibunuh Oleh')
plt.show()
#Distribusi jenis cedera
plt.figure(figsize=(12, 8))
sns.countplot(y=data['type_of_injury'], order=data['type_of_injury'].value_counts().index)
plt.title('Distribusi Data Jenis Cedera')
plt.xlabel('Jumlah')
plt.ylabel('Jenis Cedera')
plt.show()